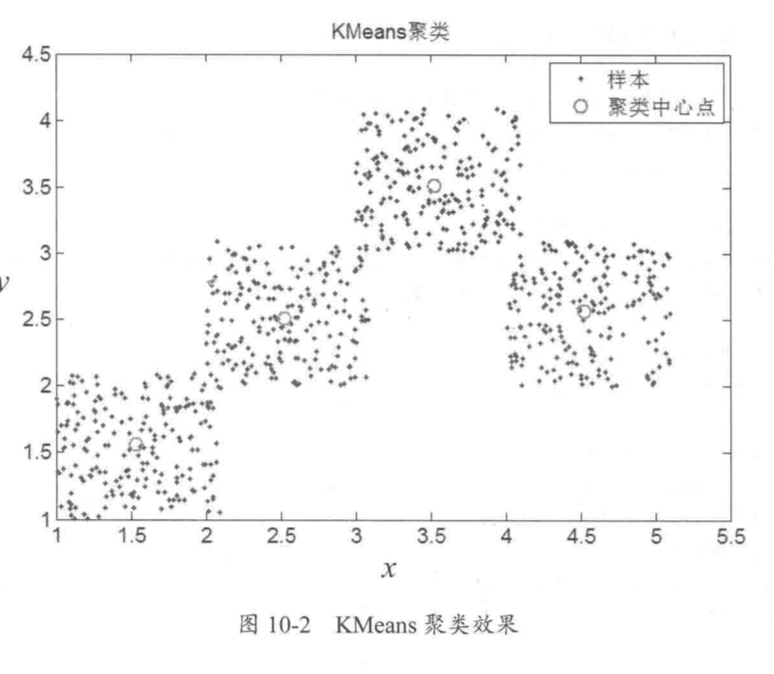
K-Means算法是一种基于距离的聚类算法,采用迭代的方法,计算出K个聚类中心,把若干个点聚成K类。
package com.immooc.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.{SparkConf, SparkContext}
object KMeansTest {
def main(args:Array[String]): Unit = {
val conf = new SparkConf().setAppName("KMeansTest").setMaster("local[2]")
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
// 读取样本数据1,格式为LIBSVM format
val data = sc.textFile("file:///Users/walle/Documents/D3/sparkmlib/kmeans_data.txt")
val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
// 新建KMeans聚类模型,并训练
val initMode = "k-means||"
val numClusters = 4
val numIterations = 100
val model = new KMeans().
setInitializationMode(initMode).
setK(numClusters).
setMaxIterations(numIterations).
run(parsedData)
val centers = model.clusterCenters
println("centers")
for (i <- 0 to centers.length - 1) {
println(centers(i)(0) + "\t" + centers(i)(1))
}
// 误差计算
val WSSSE = model.computeCost(parsedData)
println("Within Set Sum of Squared Errors = " + WSSSE)
}
}1. 输出
centers 9.05 9.05 0.05 0.05 9.2 9.2 0.2 0.2 Within Set Sum of Squared Errors = 0.030000000000043214699