是《Python 网络爬虫实战与机器学习应用》12章的例子,地址在 https://yuedu.baidu.com/ebook/8cd608073868011ca300a6c30c2259010302f34d
1.播放次数分析
chart1 = df3.sort_values('playCount', ascending=False).drop_duplicates('name')
plt.figure(figsize=(14, 6))
plt.title('baidu chart')
plt.xlabel('rank')
plt.ylabel('play count')
plt.plot(range(len(chart1['playCount'])), chart1['playCount'])
plt.show()使用sort_values进行排序
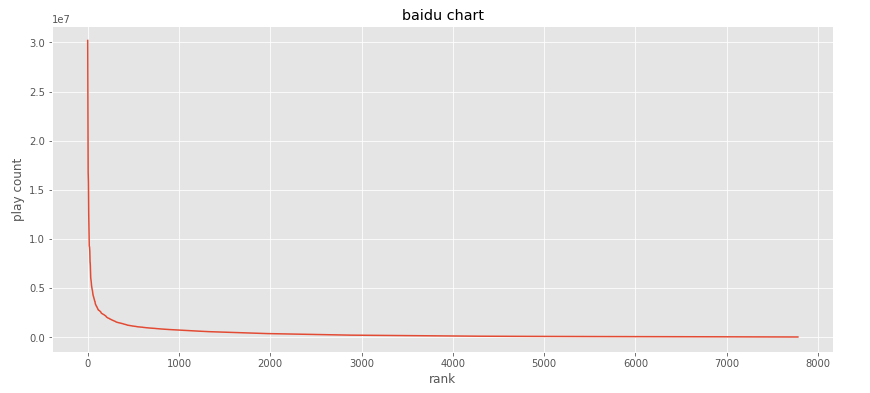
可以看到少数播放量巨大,但是大部分的播放量太低。
下面是用sql语句来,还是字符串,所以这里转一下
SELECT * FROM `gedan` ORDER by CAST(playCount AS SIGNED) DESC
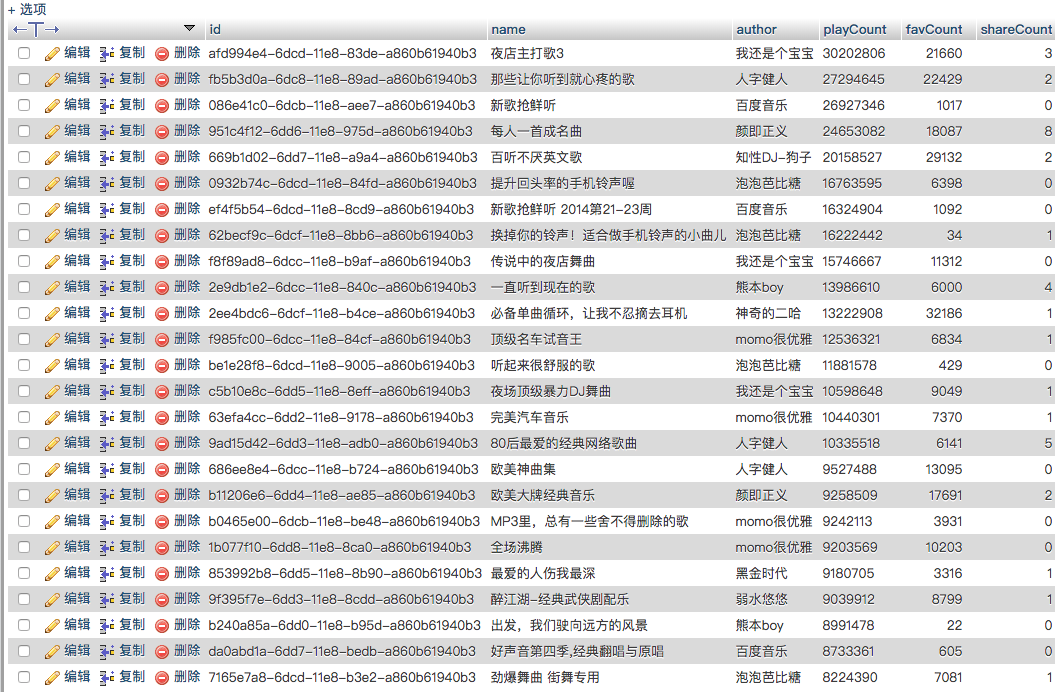
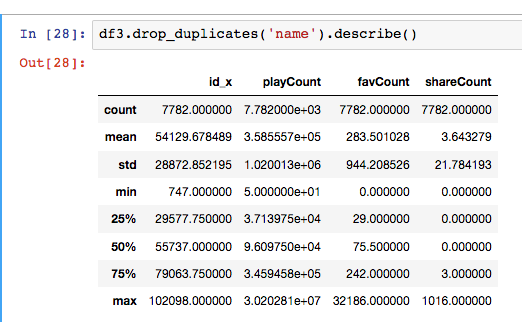
收藏次数和分享次数是类似的就不贴了。
2. 歌单里哪个歌手的歌曲数量最多
先看sql的版本:
SELECT COUNT(song_name),song_author FROM gedan_detail GROUP by song_author ORDER by COUNT(song_name) DESC
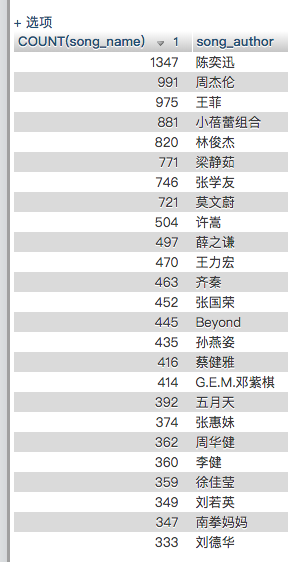
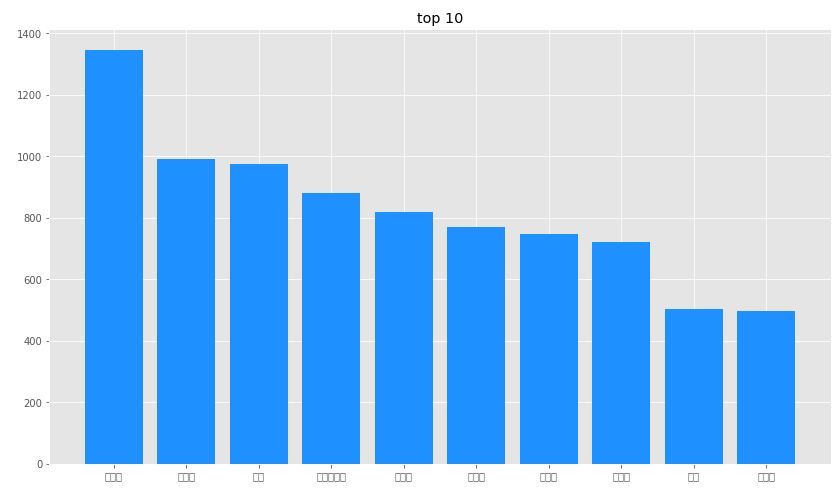
陈奕迅最多,接下来是周杰伦啥的。。。
pandas版本:
df3.groupby('song_author')['song_name'].count().reset_index().sort_values('song_name',ascending=False)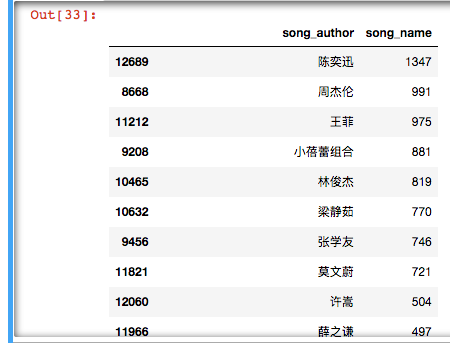
chart3=df3.groupby('song_author')['song_name'].count().reset_index().sort_values('song_name',ascending=False).head(10)
x = range(len(chart3))
plt.figure(figsize = (14, 8))
plt.title(u'top 10')
plt.bar(x, chart3['song_name'], color='dodgerblue')
plt.xticks(x, chart3['song_author'])
plt.show()
3. 根据名字group
df3.groupby('song_name')['name'].count().reset_index().sort_values('name',ascending=False)
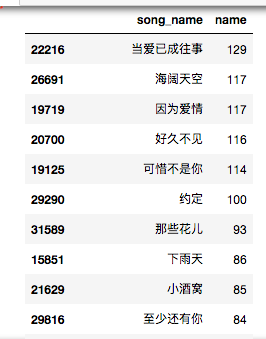
<当爱已成为往事> 出现在129个歌单中,接下来是海阔天空,因为爱情。。。
4. 播放次数和收藏次数之间的关系
df3['playCount'].corr(df3['favCount'])
0.6828233850419526
plt.figure(figsize=(14, 8))
plt.title('chart')
plt.xlabel('playCount')
plt.ylabel('favCount')
plt.scatter(df3['playCount'], df3['favCount'], alpha=0.8)
plt.show()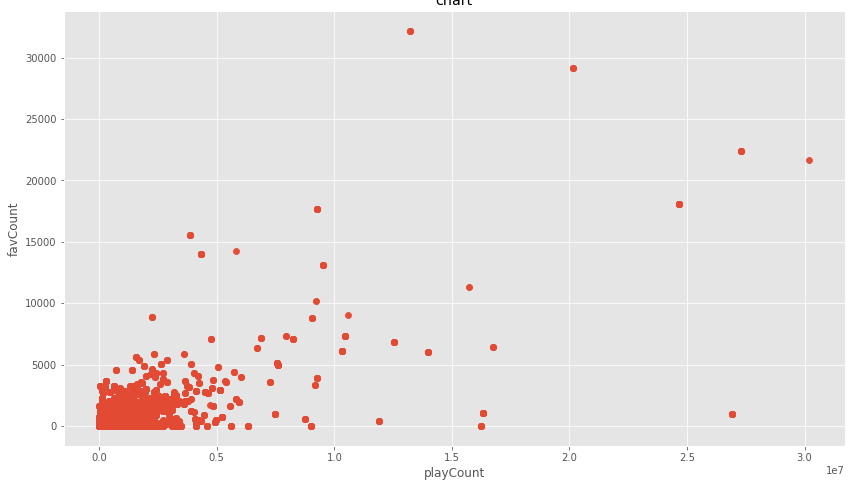
4105


